

Molmo is an open source advanced multimodal AI model that aims to improve the performance of open systems to be competitive with proprietary systems (such as commercial models), especially on academic standards and human evaluation. The Molmo model outperforms other models that are ten times larger.
Molmo is based on Qwen2-72B and uses OpenAI’s CLIP as a visual backbone, which enhances the model’s ability to process images and text.
Molmo aims to break through the limitations of current multimodal models, which usually only convert multimodal data (such as images and text) into natural language. Molmo introduces pointing capabilities to enable models to interact more deeply with physical and virtual environments, thereby supporting more complex application scenarios such as human-computer interaction and augmented reality. This capability enables future applications to process real-world information more flexibly and intelligently.
Among multimodal models of similar size, Molmo-72B outperforms, achieving the highest academic benchmark score and ranking second in human evaluation, second only to GPT-4o.
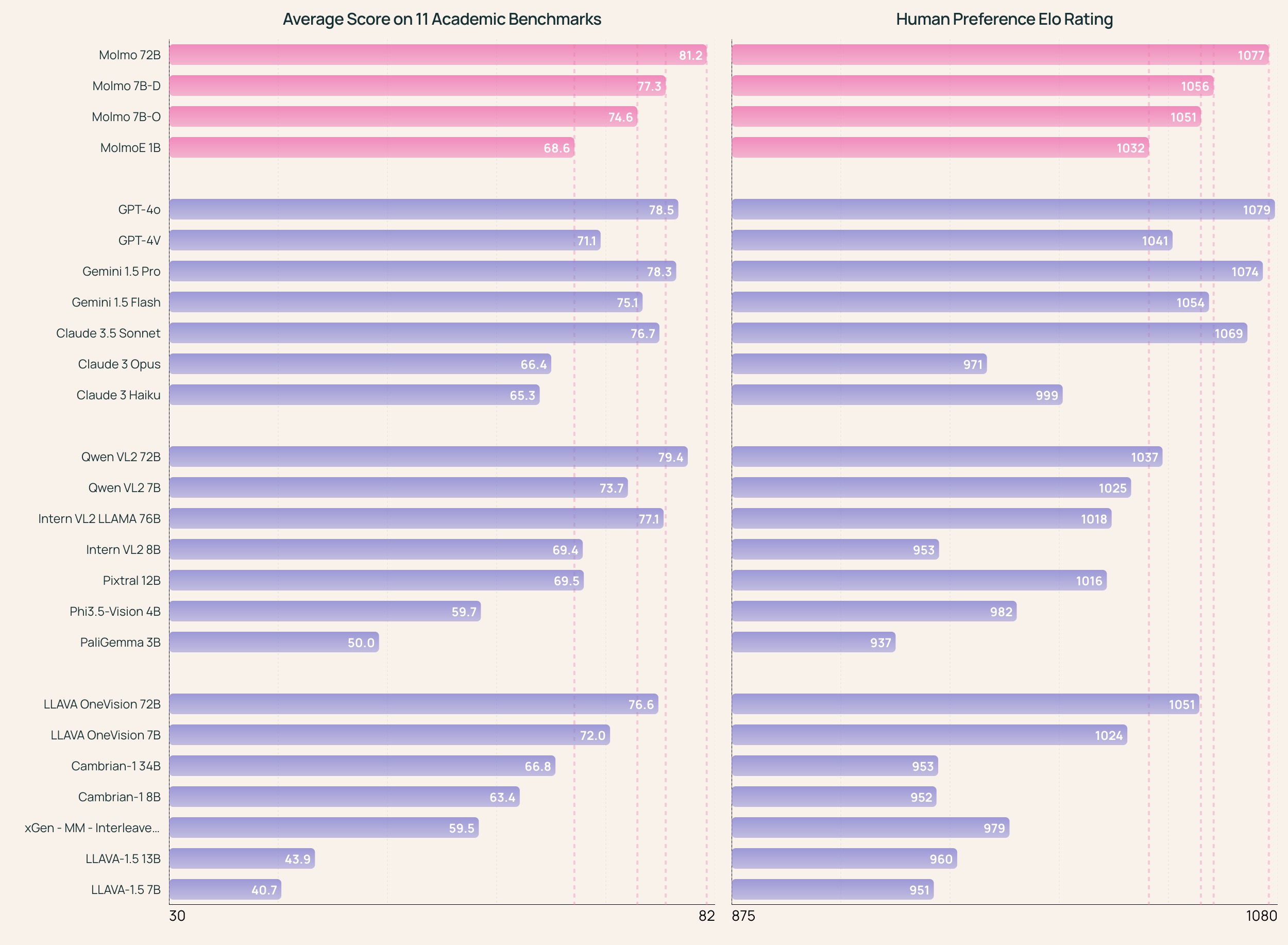
Molmo performs best among open source weights and data models, and is comparable to some proprietary systems such as GPT-4o, Claude 3.5, and Gemini 1.5.
The Molmo VLM pipeline (including weights, code, data, and evaluation) is fully open source.
Molmo’s Abilities
- Image Understanding and Generation :
- Image description : Molmo is able to generate high-quality image descriptions, understand the image content and convert it into natural language. For example, the model can identify objects, scenes, and activities in the image and generate accurate descriptions.
- Visual Question Answering : It allows users to ask questions related to images, and the model can provide accurate answers based on the image content, demonstrating strong understanding capabilities.
- Multimodal interaction :
- Combining text and images : Users can input text and images at the same time, and Molmo can effectively combine these two types of information to generate comprehensive output. This capability makes the user experience richer and more intuitive.
- Pointing and interaction : Molmo supports 2D pointing interaction, which enhances the ability to interact with visual content. For example, users can interact with objects in the image through gestures or clicks.
- High-quality data processing :
- Human-annotated dataset : The image captioning dataset used by Molmo is collected entirely by human annotators, ensuring the accuracy and diversity of the data and improving the training effect and performance of the model.
- Dynamic adaptability : The model can automatically adjust its processing method based on changes in input and adapt to different types of user interactions and data formats.
- Flexible application scenarios :
- Education : In the field of education, Molmo can be used as an intelligent teaching assistant to help students understand image and text content and enhance the learning experience.
- Entertainment : Supports a variety of entertainment applications, including games, virtual reality experiences, and creative content generation, providing an immersive user experience.
- Medical : In medical image analysis, Molmo can assist doctors in understanding medical images and provide diagnostic support.
Dataset characteristics
- scale :
- Collection method : Molmo’s dense description dataset is collected by human annotators using voice to describe images. The advantage of this method is that it can obtain more detailed descriptions and avoid the common problem of brevity in text descriptions.
- Descriptive details : Annotators are asked to describe in detail what they see in the image within 60 to 90 seconds, including the spatial location and relationship between objects. Through this method, the description information collected is more comprehensive and detailed.
- Data volume : A total of 712,000 images with detailed audio descriptions covering 50 high-level topics were collected. This dense dataset supports multimodal pre-training, enabling the model to better understand and generate image descriptions.
- Annotation Quality :
- The image descriptions in the dataset are collected by human annotators using spoken descriptions, which ensures the naturalness and accuracy of the descriptions.
- Avoiding reliance on existing VLMs : During data collection, the Molmo team avoided using existing vision-language models to ensure that they built a high-performance model that was truly built from scratch.
- Collection Challenges : Collecting dense description data from human annotators is challenging, as traditionally, simple image descriptions only mention a small number of visual elements. Therefore, Molmo’s innovative collection approach is particularly important, ensuring that the collected data is superior in detail and quality.
- Diversity :
- The dataset is designed to cover a wide range of scenarios and content, supporting multiple types of user interactions including question answering and image description generation.
- Data Sources : This data mix contains standard academic datasets as well as several newly collected datasets with the goal of making models perform well on specific tasks.
- Expanded capabilities : The newly collected datasets enable Molmo to perform a range of important functions, including:
- Answer common questions about images
- Improve OCR (Optical Character Recognition) related tasks such as reading documents and diagrams
- Reading analog clock accurately
- Point to one or more visual elements in an image, providing a natural interpretation based on the image’s pixels.
Performance
- Model comparison :
- Molmo performs best among open source weights and data models, and is comparable to some proprietary systems such as GPT-4o, Claude 3.5, and Gemini 1.5.
- Based on the assessment :
- Molmo has achieved excellent results in multiple academic benchmark tests and is evaluated using 11 commonly used academic benchmarks.
- Results collected via human evaluation methods show Molmo outperforms in user preference ranking, with over 325,231 pairwise comparisons collected, making this the largest human preference evaluation of multimodal models to date.
- Data usage efficiency :
- Compared to traditional large-scale vision-language models (usually based on billions of image-text pairs), Molmo is trained with less than 1 million image-text pairs, embodying the idea that data quality is better than data quantity.
- Function expansion capability :
- Molmo supports multiple interaction modes, such as image question answering, document reading, and pointing to specific visual elements, demonstrating its versatility in practical applications.
Official introduction and more demonstrations: https://molmo.allenai.org/blog
Model download: https://huggingface.co/collections/allenai/molmo-66f379e6fe3b8ef090a8ca19
Technical report: https://molmo.allenai.org/paper.pdf
Online experience: https://molmo.allenai.org/




")
