 Mobiles
MobilesThe DeepSeek V4 Pricing Trap: What Routing Guides Get Wrong
The DeepSeek Price War Looks Like Free Money. For Most Teams, It Is a Trap $29,580. That is the monthly savings figure circulating in every AI newsletter, Slack…
Blog
Mastering Tomorrow's Tech Today
MobilesThe DeepSeek Price War Looks Like Free Money. For Most Teams, It Is a Trap $29,580. That is the monthly savings figure circulating in every AI newsletter, Slack…
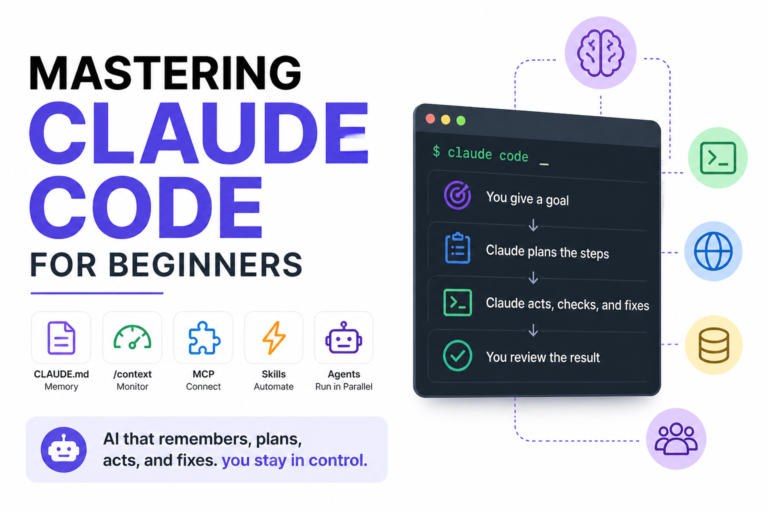
You’ve probably heard that AI can write code now. Maybe you tried GitHub Copilot once, it filled in a line or two,…
Read More
One developer ran 412 AI tool calls in a single day of heavy coding work. His total bill at the end: under…
Read More
Are you struggling with storage limitations on your new Mac Mini M4? You’re not alone. With the base model’s limited internal storage,…
Read More
In the ever-evolving landscape of technology, AI tools are rapidly becoming essential for content creators, developers, marketers, and everyday users. Here’s a…
Read More
The AI Regret Files | When Businesses Replaced Humans and Paid the Price The AI Regret Files / Investigative They Fired the…
Read More