
The DeepSeek Price War Looks Like Free Money. For Most Teams, It Is a Trap
$29,580. That is the monthly savings figure circulating in every AI newsletter, Slack channel, and LinkedIn post since April 24, 2026. Switch from GPT-5.5 to DeepSeek V4-Flash, process 100 million input tokens per day, and you bank that number every single month. The math checks out. The math is also, for the majority of development teams reading this, completely irrelevant to their actual situation.
The DeepSeek V4 pricing story is real. The 7x output cost gap between $3.48 and $30 per million tokens is real. The MIT license, the open weights, the 1.6 trillion parameter architecture running at 49 billion active parameters per inference: all real. But the way this story is being sold assumes a scale, a compliance profile, and an engineering capacity that most of the teams breathlessly sharing it simply do not have. And the gap between where they are and where the savings actually kick in is where the trap lives.
This is not an argument for GPT-5.5. This is an argument for doing the math on your actual situation before your next infrastructure decision.
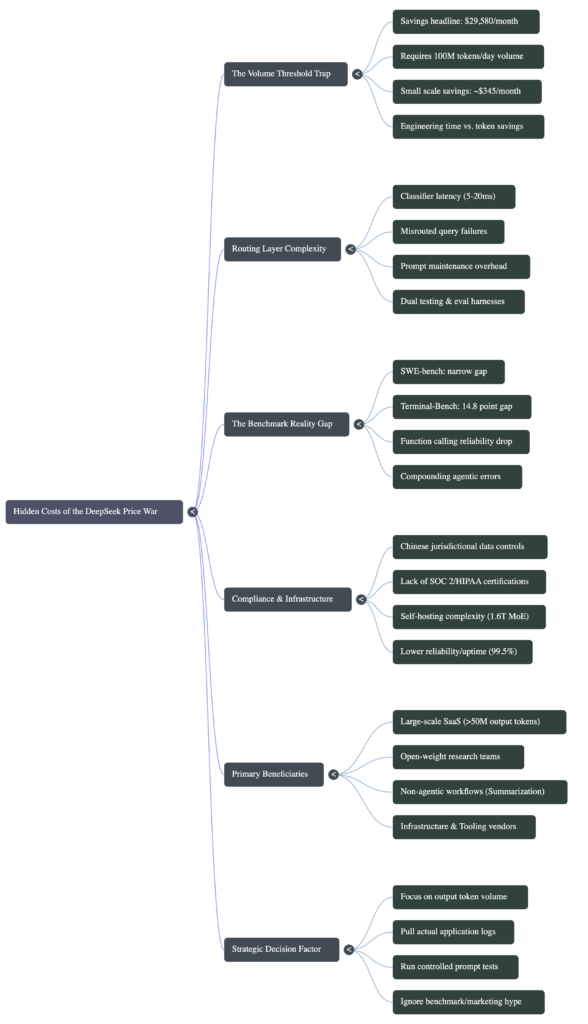
The Volume Threshold Nobody Puts in the Headline
The $29,580 monthly savings figure comes from a specific calculation: 100 million input tokens per day at $10 per million for a premium frontier model versus $0.14 per million for DeepSeek V4-Flash. That is a real calculation and a real saving for the teams processing that volume.
Here is the number nobody puts in the headline: 100 million input tokens per day is approximately 1.2 billion tokens per month. To hit that through a typical AI writing assistant, where the average prompt runs around 500 tokens, you need 2.4 million prompts per month, or roughly 80,000 per day. That is a product with serious, sustained user traction. Not a side project. Not a Series A startup with 5,000 active users.
Pull the volume down to something a real early-stage product processes, say 10 million tokens per month, and the input savings from switching to DeepSeek V4-Flash over GPT-5.5 drops to $48.60 per month. Forty-eight dollars and sixty cents. The output savings at that volume, where the per-token gap is sharpest, comes to roughly $297 per month. A combined $345 in monthly savings.
That is less than one hour of engineering time at senior developer rates. And the routing infrastructure you need to capture it costs significantly more than one hour to build, test, maintain, and keep current as both providers update their models, change their APIs, and deprecate endpoints on schedules you do not control.
What the Routing Layer Actually Costs to Build
Every article recommending multi-model routing presents it as a routing layer you install and forget. The reality of running it in production is different.
A routing layer that intelligently splits traffic between DeepSeek V4-Flash and GPT-5.5 requires a classifier that decides, for each incoming request, which model handles it. That classifier itself consumes tokens and adds latency. According to published LLMOps benchmarks, routing decisions add 5 to 20 milliseconds per request. For batch or asynchronous workflows, that is irrelevant. For user-facing chat interfaces where response feel matters, 20ms is noticeable and stacks with other latency sources.
The classifier also makes mistakes. A misrouted query, a complex agentic task sent to the cheaper model when it should have gone to the expensive one, produces degraded outputs that reach your users. You need monitoring to catch those failures, a fallback path to re-route them, and a threshold-tuning process that runs continuously as your user query distribution shifts. Static routing rules that work in week one start failing in week eight when your users discover a new use pattern your classifier never anticipated.
Then comes prompt maintenance. Prompts optimized for GPT-5.5 do not transfer cleanly to DeepSeek V4-Flash. The models respond differently to instruction phrasing, handle edge cases differently, and produce outputs with different length and formatting characteristics. Running two models in production means maintaining two sets of optimized prompts, two evaluation harnesses, and two regression test suites. Every time either provider updates a model, you test both paths.
None of this is impossible. Mature engineering teams at companies processing hundreds of millions of tokens per month do it and capture real savings. The question is whether the engineering overhead is worth it at your actual volume. For most teams reading about this on Medium or Twitter, it is not.
The Benchmark Gap Is Bigger Than It Looks on Agentic Tasks
The benchmark comparison that circulates most is SWE-bench Verified, where DeepSeek V4-Pro scores 80.6 percent against closed-model competitors in the low-to-mid eighties. That gap looks narrow. On that specific benchmark, it is narrow.
But SWE-bench Verified tests repository-level code understanding and patch generation. It does not test what happens when an AI agent runs 40 consecutive tool calls, hits a parsing error on call 23, and needs to recover context and continue. That is Terminal-Bench 2.0, which tests multi-step command-line planning and sustained tool coordination. On Terminal-Bench 2.0, GPT-5.5 scores 82.7 percent. DeepSeek V4-Pro scores 67.9 percent. That is a 14.8 point gap, not a rounding error.
On GPQA Diamond, which measures graduate-level scientific reasoning, GPT-5.5 scores 93.6 percent versus DeepSeek V4-Pro at 90.1 percent. Three and a half points on reasoning-heavy queries.
NIST’s independent evaluation, using non-public benchmarks across cyber, software engineering, natural sciences, abstract reasoning, and mathematics, placed DeepSeek V4 at a capability level equivalent to GPT-5.0, a model released approximately eight months before V4. DeepSeek’s own self-reported evaluations show V4 matching Claude Opus 4.7 and GPT-5.4. The NIST number and the DeepSeek number cannot both be right, and the independent source with non-public test sets is the more credible one.
Function calling reliability adds another dimension to this. Independent testing shows DeepSeek V4 correctly formats function calls 91 percent of the time on schemas with five or more parameters and nested objects, versus 95 percent for GPT-5.4 on the same schemas. Four points sounds small. In an agentic workflow that chains 20 function calls, a 4-point reliability drop per call compounds to a meaningful increase in complete-pipeline failure rate. For applications where every tool call matters, that compounding is not a theoretical concern.
The Compliance Bill That Does Not Appear in the Pricing Calculator
DeepSeek V4-Flash costs $0.14 per million input tokens. That price is real. What that price does not include is the compliance cost of sending your data through infrastructure subject to Chinese jurisdictional controls.
DeepSeek’s hosted API routes traffic through servers under a different legal framework than AWS us-east-1 or Google Cloud europe-west4. For a personal project or an internal developer tool processing non-sensitive queries, this is probably fine. For applications handling any personally identifiable information, protected health information, financial data, or content subject to EU GDPR, this is a real legal exposure that your legal counsel will want to review before you route a single production request.
OpenAI and Anthropic carry SOC 2 Type II certifications, HIPAA Business Associate Agreements, and enterprise SLAs with contractual uptime guarantees. DeepSeek’s hosted API, as of this writing, does not match that compliance portfolio. This is not a critique of DeepSeek’s intentions. It is a factual description of what enterprise procurement teams require before they sign off on a vendor.
The self-hosting path using V4’s MIT-licensed weights eliminates the data routing concern entirely. But self-hosting a 1.6 trillion parameter MoE model is not a weekend project. The compute requirements, infrastructure management, and operational overhead represent a meaningful investment that belongs in your cost-benefit calculation alongside the token price savings.
DeepSeek’s hosted API also shows measurable reliability differences from established providers. Independent uptime monitoring places it at 99.5 percent, versus 99.9 percent or better for OpenAI and Anthropic. That half-point difference translates to roughly 3.6 additional hours of downtime per month. For batch workloads and internal tools, that is manageable. For user-facing applications where availability is a product promise, your engineering team absorbs the cost of handling those outages.
Who the Price War Actually Benefits
None of this means the DeepSeek V4 pricing story is wrong. It means it applies clearly to specific teams and gets oversimplified when sold as universal advice.
The price war genuinely changes the math for large-scale SaaS companies processing hundreds of millions of tokens per day. At that volume, even a partial routing shift to V4-Flash produces savings that fund engineering headcount. The complexity cost of the routing layer becomes a rounding error against the infrastructure savings.
It genuinely benefits research teams who need open weights for reproducibility, fine-tuning, or deployment in air-gapped environments. MIT license, downloadable weights, runs on hardware you control: that combination has real value independent of the per-token price.
It benefits teams building specifically on non-agentic workflows. Summarization, classification, extraction, translation, and light reasoning tasks where the 14-point Terminal-Bench gap is irrelevant to your actual use case. If your application generates structured data from documents and the quality difference between V4-Flash and GPT-5.5 on that specific task is less than 3 percent, the 7x cost difference is a legitimate argument for switching.
It benefits developers building infrastructure around the price war itself. The LLM router, gateway, and observability tooling market is growing faster than the model market right now. Those companies need a large price gap to sell against. DeepSeek V4 and GPT-5.5 existing simultaneously is their product-market fit.
The One Question That Tells Which Side You’re On
Before you architect a multi-model routing layer based on the savings math circulating this month, answer one question with actual numbers from your application logs.
How many output tokens does your application generate per month today?
Not input tokens. Output tokens, because output drives the cost that the pricing war is actually about. GPT-5.5 charges $30 per million output tokens. DeepSeek V4-Pro charges $3.48. The gap is $26.52 per million output tokens.
If your current monthly output token volume is below 10 million tokens, the savings from switching are under $265 per month. If your application is user-facing and latency matters, if your use case involves multi-step agentic tasks, or if you operate in a regulated industry, that $265 does not cover the cost of the engineering time you spend on the switch, let alone the ongoing maintenance.
If your output volume is above 50 million tokens per month, the calculation shifts. At that scale, the savings are real enough to justify the routing infrastructure investment and potentially worth pursuing even with the compliance and reliability tradeoffs factored in.
The number most teams discover when they actually pull their logs is somewhere between those two points. And in that middle range, the honest answer is: run a controlled test on your specific prompts, measure quality on your actual outputs, and make the decision based on that data rather than a savings headline designed to get clicks.
The price war between DeepSeek V4 and GPT-5.5 is real. The winner of that war, for most teams, is not DeepSeek and not OpenAI. It is the team that stops reading about it and spends 30 minutes pulling their actual token logs.
Check your logs before you check your Twitter feed. The number in your database is more useful than any benchmark you read this week.